webscrapers on steroids
2024-05-01It’s May! That means I’ve been working on the SIREN project at the Centre for Mental Health Law and Policy for an entire year. Our monolith has changed drastically since we started. From just a single scraper for Telegraph India, we now have coverage of 8 different publications, complete with a data validation and cleaning layer. These webscrapers go through E-paper catalogs to find articles that report on suicide, extracting the metadata of relevant articles and putting it in a spreadsheet for researchers to use. As you can imagine, this saves a lot of time that would otherwise be spent on manually finding these articles.
the good part
Turns out that most (note the italics) epapers have a searchbar you can use to search up particular keywords. How dandy! This ‘solves’ the biggest struggle with webscraping epapers: dealing with the data format. Scraping textual data is a bajillion times easier than scraping binary data which should be textual; like images of text. And epapers are exactly that. Thankfully, the publications do store the text in their private little database, and their internal APIs query that database whenever someone uses the search function on the webpage. These endpoints are easy to find and exploit to anyone who knows how to use their browser’s developer tools and some basic python.
For example, searching for the 10 latest Star Wars articles on News Minute is a simple HTTP GET request:
import requests
resp = requests.get("https://www.thenewsminute.com/api/v1/advanced-search?q=star%20wars&limit=10&offset=0&fields=url,headline,published-at")
print(resp.json())But what if we needed all of News Minute’s star wars content? Let’s add in some pagination:
import requests
def get_page(page: int = 0, *, page_size: int = 100):
offset = page_size * page
resp = requests.get(
f"https://www.thenewsminute.com/api/v1/advanced-search?q=star%20wars&limit={page_size}&offset={offset}&fields=url,headline"
)
return resp.json()
PAGE_SIZE = 100 # the amount of articles from each query
data: list[dict[str, str]] = []
initial = get_page(page_size=PAGE_SIZE)
data.extend(initial["items"])
total = initial["total"] # the total amount of articles
pages = (total // PAGE_SIZE) + 1 # the number of queries we need to make
for i in range(1, pages):
sr = get_page(i)
data.extend(sr.get("items", []))
print(data)If you try to run this code, it will take about 2 minutes for it to finish. This is because python code executes sequentially; whenever we make a request, we wait for it to finish before sending the next one. This is really terrible for performance, because the time spent in simply waiting for a response from the News Minute servers is precious time our processor could use for other things.
This is where we make things asynchronous. All that means is we’ll be telling our code when it needs to wait for some I/O to happen, like getting a response from a server, so that it can do some other work in the meantime. This could also be something like reading from a disk; where the work is not computationally expensive, but rather bound by the time taken for I/O. These kinds of “I/O bound” programs benefit greatly from Cooperative Multitasking, which is the async/await concurrency model. We’ll talk more on this later.
To make our code async, we’ll first switch from the requests package, which executes synchronously, to httpx (aiohttp is also a great choice).
import httpx
import asyncio
async def get_page(page: int = 0, *, page_size: int = 100, client: httpx.AsyncClient):
offset = page_size * page
resp = await client.get(
f"https://www.thenewsminute.com/api/v1/advanced-search?q=star%20wars&limit={page_size}&offset={offset}&fields=url,headline"
)
return resp.json()
async def main():
PAGE_SIZE = 100
async with httpx.AsyncClient(timeout=None) as client:
initial = await get_page(page_size=PAGE_SIZE, client=client)
total = initial["total"]
pages = (total // PAGE_SIZE) + 2
tasks: list[asyncio.Task[dict[str, str]]] = []
for i in range(1, pages):
task = asyncio.create_task(get_page(i, client=client))
tasks.append(task)
results = await asyncio.gather(*tasks)
data = initial["items"]
for sr in results:
if items := sr.get("items"):
data.extend(items)
print(data)
asyncio.run(main())Whoa! It looks quite different now. Let’s see what’s changed:
- The
get_pagefunction now has theasyncprefix in it’s definition - The first call to
get_pagehas anawaitprefix - The pagination logic is inside the
mainfunction async with?asyncio.gather?asyncio.run?
First, off: Coroutines. These are special functions which can be suspended and resumed.
These are created primarily with the async def syntax. They’re also called async functions to distinguish them from coroutine objects, which are what they return.
Our code has two coroutines; get_page and main. When we call them, we get a coroutine object. You can open an asyncio REPL with python -m asyncio and try it out:
>>> async def foo():
... print("bar")
...
>>> foo()
<console>:1: RuntimeWarning: coroutine 'foo' was never awaited
RuntimeWarning: Enable tracemalloc to get the object allocation traceback
<coroutine object foo at 0x7afdfcbfa9240>Oh, a RuntimeWarning? That’s because calling foo() doesn’t actually execute it; as you can see, “bar” was never printed.
As the warning says, we need to await it.
>>> async def foo():
... print("bar")
...
>>> await foo()
barIn essence, await will suspend the execution of the currently running awaitable (like a coroutine) and yield control to the event loop, so that another task may take place.
Once we’ve made the initial query, we get the total number of articles. With that information, we know how many queries we need to make;
and hence there is no need to make those queries sequentially (making the nth query doesn’t require us to know the result of (n-1)th query).
Instead, we use the asyncio.create_task method to schedule execution of the coros.
We maintain a reference to these tasks inside the tasks list, which we’ll pass to asyncio.gather.
This will block till all the tasks are done, and all our data has been received.
Finally, we need to create the event loop and run our main() coro; we use the asyncio.run function for this.
Lets compare benchmarks:
Our vanilla, sync script:
Executed in 141.38 secs fish external
usr time 2.18 secs 189.00 micros 2.18 secs
sys time 0.11 secs 106.00 micros 0.11 secsVersus the shiny new async script:
Executed in 7.25 secs fish external
usr time 1.28 secs 243.00 micros 1.28 secs
sys time 0.14 secs 136.00 micros 0.14 secsWe get a 20x performance increase with the async version! This is how most SIREN scrapers work; exploiting an internal search api and making requests concurrently to get fast results. Well, that’s if such an api exists…
the bad part
Some publications don’t have a convenient search bar. Or they do, but it’s broken or extremely inaccurate. This makes my job significantly harder. We don’t have any textual data to work with; we have images. Extracting text from images (a process called OCR) is extremely taxing on the cpu. Not only does it take a lot of compute power, it also takes a lot of time. This is also in part due to the degree of accuracy needed from the SIREN scrapers; we can only use high-resolution images to ensure sufficient precision. OCR is “CPU-bound” work, and async doesn’t help here; there’s no waiting time, because the CPU is constantly crunching numbers. Sad face :( In these cases, we use thread-based parallelism, to utilize all our cpu cores and run multiple OCR tasks in parallel. This is very janky in python due to it’s gil. But I won’t get into that… for now.
a note for publications
You won’t believe the things I’ve seen. The horrors I’ve witnessed.
This fakeAmountINR field, for example, from the Indian Express:
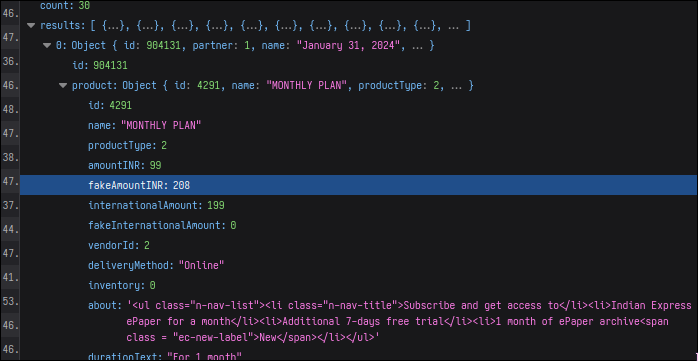
Isn’t the whole “fake discount” thing illegal?
Or this snippet from the Hindustan Times:
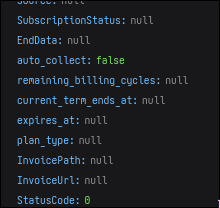
is it so difficult to have consistent naming conventions :/ I know no one is supposed to be using this stuff… but still.
Alternatively, it would be amazing if publications would work with researchers and give them easy access to the data they need. This whole webscraping business is only happening because there is no proper channel for researchers to access vital data.
In any case… looks like I’m going to need a whole lot of eye bleach now.
thanks for reading! if you have any suggestions, questions, criticism, et al: my contacts are in the footer.